视觉是人类最高级别的感知,因此图像在人类感知中扮演着重要的角色。统计表明,人类从外界获得的绝大部分信息是来自视觉所接收的图像信息。随着计算机软硬件技术、社交网络和多媒体技术的快速发展,图像的生成、处理、存储、传播变得越来越方便,图像数据量呈现出爆炸性的增长。58作为国内排名前列的生活服务平台,存储有海量的图像数据。如何使用好这些图像数据涉及到各种类型的图像任务,常见的有:图像审核、图像分类、人脸识别、OCR、目标检测、图像检索、图像质量评价等。图像特征提取往往是处理这些任务的第一步,也往往是关系任务成败的重要一步。本文对作者所在团队在图像特征提取方面的一点实践做一个简要总结。
二、特征提取图像特征多种多样,不同的任务会用到不同的特征。出于适应多种常见任务的考虑,实践中提取了3种类型图像特征。
2.1 传统全局特征
全局特征描述图像整体的信息,常见的全局特征有颜色、形状、纹理等。全局特征计算简单、表示直观,但容易受到光照、旋转、噪声等干扰。实践中提取了与视觉感知直接相关的平均色调、平均饱和度、平均亮度、清晰度、对比度等特征。
2.2 局部特征
局部特征描述图像局部区域的信息,代表的是图像上的一些特殊点或特殊局部区域,如角点、边缘、斑点等。不同图像可能有不同数量的局部特征。该类特征通常是为了鲁棒地处理各种图像变换而设计,因此通常具备旋转、缩放、亮度变化不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。
局部特征提取分为两步:特征点检测和特征点描述。特征点检测的作用是从图像中定位到特征点,常用算法有DOG、LOG、MSER、Hessian affine、Harris-Hessian、FAST等。特征点描述的作用是用一个向量来表示检测到的特征点,常用算法有SIFT描述子、PCA-SIFT描述子、ROOT-SIFT描述子、SURF描述子、BRIEF等。
局部特征提取算法非常之多,实践中提取了SIFT、SURF、ORB等特征。SIFT(Scale Invariant Feature Transform)是众多局部特征中应用最广的,SIFT的提出是局部图像特征描述子研究领域一项里程碑式的工作。SIFT对尺度、旋转以及一定视角和光照变化等图像变化都具有不变性,并且SIFT具有很强的可区分性,自它提出以来,很快在物体识别、宽基线图像匹配、三维重建、图像检索中得到了应用。SURF(Speeded Up Robust Features)是对SIFT的改进版本,SURF的速度是SIFT的3-7倍,大部分情况下它和SIFT的性能相当,因此它在很多应用中得到了应用,尤其是对运行时间要求高的场合。ORB(Oriented FAST and Rotated BRIEF)也是一种常用的局部特征,最大的特点就是计算速度快。三者比较,SIFT特征在效果方面通常优于SURF和ORB,但速度最慢。ORB是三者中速度最快的但效果不如前二者。
单张图像通常有很多个局部特征,这些局部特征会构成一个矩阵。当处理某些图像任务时,需要由这个矩阵出发得到一个表示整个图像的向量,因此需要利用特征编码算法对其进行编码。3个非常流行特征编码算法有:BOF(Bag-of-Visual-Words)、FV(Fisher Vector)、VLAD(vector of locally aggregated descriptors)。BOF、FV、VLAD都需要对得到的局部特征进行聚类,得到一个码本,利用码本,将原始的向量映射到新的向量空间中,不同之处在于映射方法不同。编码之后得到的特征通常继承了局部特征的部分不变性。
2.3 CNN特征
自2012年AlexNet在ImageNet分类任务中赢得冠军之后,CNN(卷积神经网络)在图像处理方面得到更广泛的应用。典型的CNN模型由若干个卷积层 池化层堆叠后再加上少数全连接层组成。通常认为,在模型网络中越深的层提取到的特征包含的语义越高层。位于网络低层的卷积层检测到的是局部视觉模式,提取到的是low-level的特征。位于网络高层的全连接层具有全局表示性,提取到的是high-level的特征。CNN特征可使用预训练模型、预训练 微调模型这两类模型来提取。预训练模型是他人在大型数据集(如ImageNet)上训练后公开的模型。预训练 微调的模型是在预训练模型的基础上用任务数据集自己做微调得到的模型。微调时使用到任务数据集,因此更可能得到对任务有高区分度的特征。实践中提取了VGG16的fc2层特征与Xception模型avg_pool层特征。
三、应用3.1 图像检索
图像检索,简单的说,便是从图像数据库中检索出满足条件的图像。用户使用图像检索系统的3种主要类型为:1、实例检索,即从图像库中查找出与查询图像相同或相似的图像;2、类别检索,即从图像库中查找出与给定查询图像属于同一类别的图像;3、相关检索,即在图像库中无特定目标的浏览式检索以发现感兴趣的图像。图像检索系统的核心:1、图像表示,即用一个固定长度的向量来表示图像,涉及到特征提取和特征编码;2、索引构建,为实现高效检索而构建索引,两种流行的索引技术是倒排索引和哈希索引;3、打分,度量查询图像与索引库中图像的相似度;4、重排序,对初始检索结果做进一步优化,三种有效的重排序手段是几何验证、查询扩展和多系统融合。图像特征提取是图像检索任务中第一个要解决的问题。对图像提取本文第二部分提到的部分特征,在实例检索任务和类别检索任务上实验,相关情况如下。
构建数据集:
1、实例检索图像集:共2000张图片,200张原始图片,每张图片经过灰度、裁剪、旋转、文字水印、图片水印等10种变换后得到。从同一张原始图片变换得到的图片定义为同源图片
2、实例检索查询图像集:实例检索图像集中随机抽取100张
3、类别检索图像集:共2000张。笔记本、单车、二手轿车、二手手机、客车、商铺、手表、挖掘机、洗衣机、租房等10个类别,每个类别各200张图片组成。构建该数据集时,每个类目都会先选取500张初始图片,计算 phash后删除重复图片,人工审核剔除类别错误、广告、无关、低质图像后保留200张
4、类别检索查询图像集:类别检索图像集中随机抽取100张
实验步骤:
1、提取图像特征
局部特征选择SIFT、SURF、ORB特征,特征编码方式选择BOF和VLAD
Xception模型avg_pool层特征
2、资源训练
BOF码本训练:对所有图片的所有局部特征做聚类,每个聚类质心即为一个visual vord,所有聚类质心的集合即为码本。聚类数是一个输入参数,聚类数即为码本的大小。码本大小一般都为数千、数万、数十万。BOF特征是基于单张图片的所有局部特征在码本上的分布直方图来计算的,特征维度与码本大小相同。
VLAD的聚类质心训练:对所有图片的所有局部特征做聚类,获取到聚类质心的集合,以便生成原始的高维VLAD特征。原始的高维VLAD特征维度为聚类质心数乘以局部特征的维度,维度一般高达数万数十万维。聚类数是一个输入参数。
VLAD的PCA训练:作用为降维。用PCA将原始的高维VLAD特征压缩为一个数百维的特征,以利于构建索引
3、索引构建
采用工具提供的倒排索引,未使用Product Quantization对图像特征做压缩。构建时对索引图像集聚类,将聚类质心作为key,归属于该质心的图像列表作为value构建倒排索引,相似度度量采用L2。
4、查询
对查询图像提取特征后,计算查询图像与索引中各个key的距离,之后该查询图像被指派到距离最近的少数几个key,计算查询图像与这几个key对应的value中的图像的相似度,按相似度排序取top10
5、效果统计
统计top10结果的效果
实验工具:
opencv、keras、faiss
效果指标:
实例检索:top10结果的平均相似准确率
类别检索:top10结果的平均类别准确率
实验结果:


实验结果解读:
1、类别检索情形下,Xception模型的avg_pool层的特征表现明显优于SIFT特征。Xception模型的目的就是图像分类,是在ImageNet比赛的1000类共120万张图片的大型数据集上训练得到的。类别检索图像集中的笔记本、客车、轿车、洗衣机、手机、手表等类别包含在这1000类中。类别检索图像集与比赛图像集有某种程度的相似性,预训练模型提取出的特征很好的表征了类别。
2、实例检索情形下,SIFT特征的表现优化基于Xception模型的avg_pool层的特征。SIFT特征是局部特征,本质上是散布在图像上的特殊局部区域,旋转、切割、水印等变换后,同源的任2张变换图一般都会存在一些共同的特殊局部区域,经过特征编码,同源的2张图片的向量会有更大的可能性在较多维度上的值比较接近。
3、在需要快速搭建图像检索系统时,类别检索可直接用CNN提取特征,实例检索用SIFT等局部特征。
后续方向:
1、不同预训练CNN模型、不同层的特征效果对比
2、特征融合,卷积神经网络浅层与高层特征融合、人工设计特征与卷积神经网络特征融合、人工设计特征局部特征与全局特征融合
3、构建更大的自有图像集,采用预训练 微调模型提取不同层特征
3.2 图片质量评价
图像在获取、传输、处理、存储的过程中很容易发生退化,严重的退化会导致呈现给图像观察者的视觉效果非常差。依靠评测人员主观打分的图像质量评价方法费时费力,自动的、快速的客观图像质量评价方法才能满足需求。客观图像质量评价方法根据需要原始参考图像的程度可以分为三种类型:全参考方法、半参考方法、无参考方法。在实际工作中,通常是在完全没有原始参考图像的情形下计算当前图像的质量评分,因此采用无参考质量评价方法。对无参考图像质量评价的常用公开数据集的图像提取本文第二部分提到的部分特征做实验,相关情况如下。
构建数据集:
1、训练集:TID2008(共1700张,17种退化类型)、CSIQ(共866张,6种退化类型)
2、测试集:LIVE(共982张,5种退化类型)
实验步骤:
1、提取图像特征
Xception模型avg_pool层特征
2、资源和模型训练
特征最大值最小值文件:作用是对特征做标准化
二分类SVM模型
3、预测质量评分及分析效果
对LIVE数据集图像打分并计算效果指标
对自有图像打分并人工评估
实验工具:
keras、sklearn
效果指标:
准确率、召回率、AUC
实验结果:
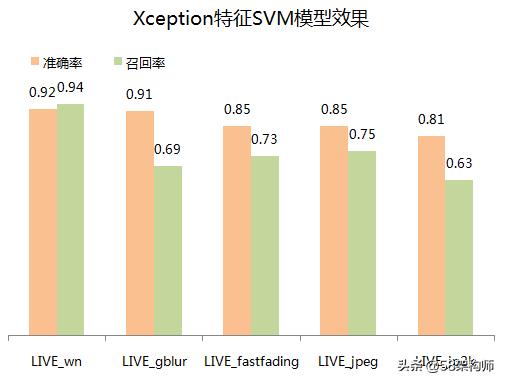
实验结果解读:
1、在LIVE上的准确率尚可接受,召回率部分退化类型偏低。
2、实验用图像数据量仍然偏少,不一定有普遍的代表性。
后续方向:
1、构建自有业务的图像质量数据集做实验
2、用局部特征、不同CNN模型、CNN模型不同层特征做实验
3、基于不同退化类型分别实验
4、人工评测工具
3.3 其他
在CTR预估方面,可以只使用图像特征作为feature训练CTR模型,可以将图像特征与其他特征一起作为feature训练CTR模型,可以将图像质量评价任务中的图像评分作为一个特征与其他特征一起作为feature训练CTR模型。对特征的应用有多种方式可选,作者团队只在某个方式上做过实践,因此对效果就不再列举。从已做的单个方式的实验来看,CTR提升并不明显。当然,单个方式的实验并不足以说明图像特征在CTR预估方面的效果,有待进一步实验。在图片去重方面,可以考虑使用实例检索任务中效果较好的Sift_VLAD_cluster128_dim256或Sift_VLAD_cluster128_dim128,将图像表示为一个256维或128维的向量,具体在线上系统中如何使用还需要进一步阅读文献。图像特征在首图优选、图像审核等任务上的应用及效果,有待进一步实践。
四、总结本文简要介绍了作者所在团队在图像方面的一点实践。文中提到的部分图像特征有着一定程度的任务适应性,可用于多个不同的图像任务。图像特征多种多样,特征提取方法也非常之多,逐一深究毫无必要。实际工作中,根据面对的具体任务,提取相应的特征,实现相应的成熟算法,方为上策。
欢迎大家关注“58架构师”微信公众号,定期分享云计算、AI、区块链、大数据、搜索、推荐、存储、中间件、移动、前端、运维等方面的前沿技术和实践经验。
,











