今天给大家分享下Serialize/Deserialize指令的运用----也就是序列化与反序列化。
首先介绍下它们的概念:
序列化:可以使用“序列化”指令将多个 PLC 数据类型 (UDT)、STRUCT 或 ARRAY of <数据类型> 转换为顺序表示,而不会丢失结构部分。
反序列化:可以使用“反序列化”指令反向转换 PLC 数据类型 (UDT)、STRUCT 或 ARRAY of <数据类型> 的顺序表示并填充所有内容。
学习过其它高级语言比如Java或者PHP的小伙伴可能会很熟悉,序列化最重要的作用:在传递和保存对象时,保证对象的完整性和可传递性。对象转换为有序字节流,以便在网络上传输或者保存在本地文件中。 反序列化的最重要的作用:根据字节流中保存的对象状态及描述信息,通过反序列化重建对象。 核心作用就是对象状态的保存和重建。
而西门子博途SCL语言中的序列化与反序列化指令作用与之类似,都是在数据的移动与操作时,更好的保存与重建。具体运用比如:PLC与上位机通讯做数据交换时,需要打包发送数据,或者解析上位机的发过来的数据时可以使用此指令保证数据结构的完整性。
下面我们具体看看指令的含义与运用:
- 序列化Serialize
Serialize(SRC_VARIABLE:=_variant_in_, DEST_ARRAY=>_variant_out_, POS:=_dint_inout_);
下表列出了该指令的参数:
参数 | 声明 | 数据类型 | 说明 |
SRC_ARRAY | Input | VARIANT | 指向一个待序列化的 STRUCT、ARRAY 或 PLC 数据类型 (UDT) 变量的指针。 |
DEST_VARIABLE | Inout | VARIANT | 指向保存所生成数据串的 ARRAY of BYTE 或 ARRAY of CHAR 的指针。 |
POS | Inout | DINT | POS 参数处的操作数,将根据已转换客户数据所占用的总字节数,存储第一个字节的下标。POS 参数将从 0 开始计算。 |
函数值 | INT | 错误代码 | |
- 反序列化Deserialize
Deserialize(SRC_ARRAY:=_variant_in_, DEST_VARIABLE=>_variant_out_, POS:=_dint_inout_);
下表列出了该指令的参数:
参数 | 声明 | 数据类型 | 说明 |
SRC_ARRAY | Input | VARIANT | 指向用于保存数据串的 ARRAY of BYTE 或 ARRAY of CHAR 的指针。 |
DEST_VARIABLE | Inout | VARIANT | 指向一个待取消序列化的 STRUCT、ARRAY 或 PLC 数据类型 (UDT) 变量的指针。 |
POS | Inout | DINT | POS 参数中的操作数将根据转换后客户数据所占用的字节数,存储第一个字节的下标。POS 参数将从 0 开始计算。 |
函数值 | INT | 错误代码 | |
关于各自的错误码含义,可以在博途软件F1帮助中查看。
- 下面我们看一个实例:通过新建三个数据块来举例并监控这两个指令的运用:
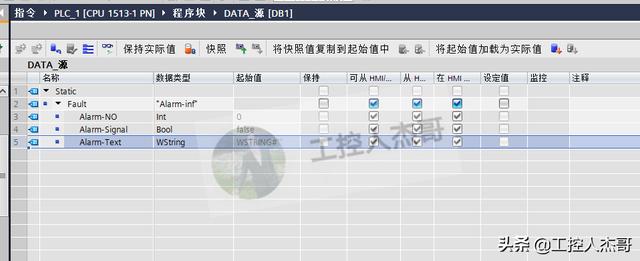
数据块1:DATA源数据;
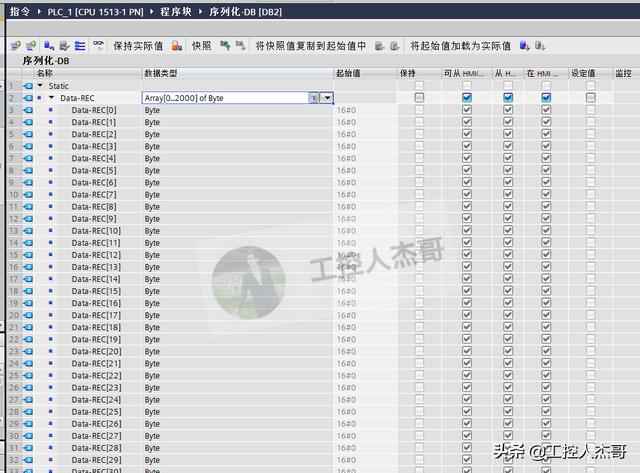
数据块2:序列化数据;
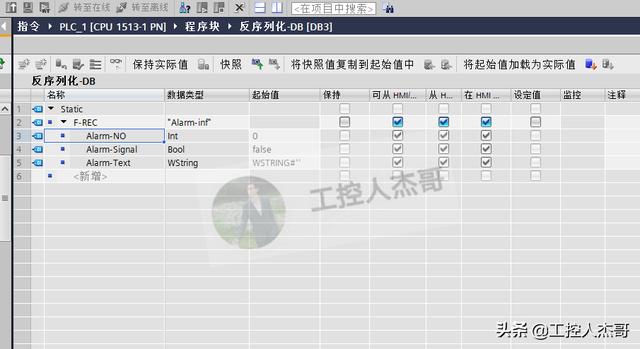
数据块3:反序列化数据;
要求首先把源数据1序列化到数据块2,然后再反序列化到数据块2中。
1.首先新建一个UDT用户自定义数据类型,如下:

2.分别建立3个全局数据块DB1、DB2、DB3如下:
3.开始编写程序,新建一个FC块,并声明好接口变量:

4.最后在OB1中调用FC,填写好接口:
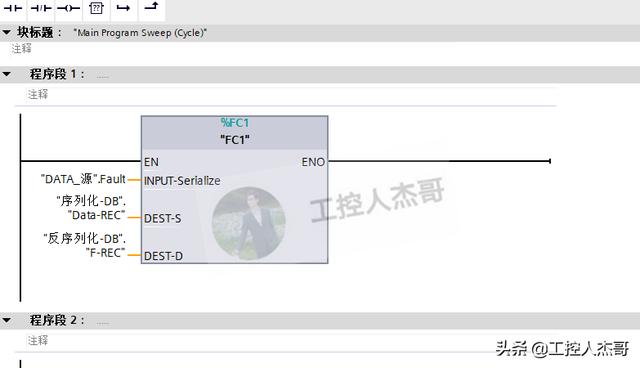
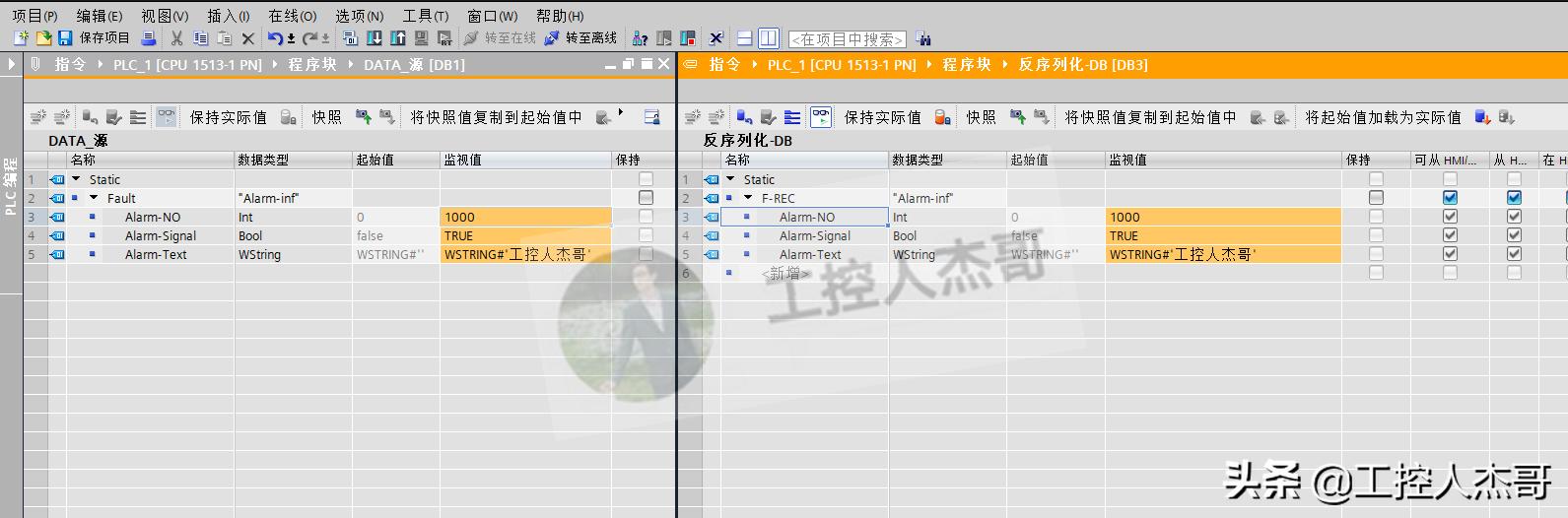
5.数据仿真演示:
按照我们的逻辑,结果应该是源数据中改变内容后我们相对应的DB3反序列化数据块内容也应该跟着改变,而我们仿真出来的结果也验证了这一点。


以上即为本章内容,大家可以跟着验证一遍,加深印象,感谢阅读!
,